Introduction
Generation of new content in the format of text, video, or audio using Generative Artificial Intelligence (GenAI) is widely gaining popularity these days. The advancements in Large Language Models (LLMs) which can generate human-like text have huge potential in various realms of engineering. These models have made it possible to use GenAI in a wide range of applications through prompt engineering. However, the responses generated by the LLMs are confined to the trained knowledge of the model. To overcome this limitation, certain methods can be applied like fine tuning the LLM, in-context learning, or retrieval augmented generation (RAG).
Methodology
Fine tuning involves retraining the already pre-trained model with a custom dataset to perform a particular task [1]. However, fine tuning LLMs are expensive and resource intensive, which makes it inaccessible to many. Apart from this, fine tuning becomes impractical if the data is constantly changing or being updated as this will require continuous fine tuning for the model to stay relevant. In-context learning [2] allows the LLM to perform a task with the help of some examples of how the output must be generated from input, without the need for any parameter updates or fine tuning. This method can be used to generate responses based on additional information given as context to the prompt. The model can adapt quickly with the context and respond accordingly. However, this approach fails when the context becomes too large to be incorporated into the LLM input and manually adding required information as context, for each query is impractical.
In such cases, the technique called RAG [3], [4] can be applied. Using this technique, the LLM can be made to generate responses based on large private data with which the model has never been trained before, without any fine tuning. RAG combines the generative capabilities of the LLM along with an information retrieval system thereby automating the process of fetching relevant information from the data which can be incorporated into the prompt. This is highly effective in avoiding wrong responses or misinformation from the model (known as hallucinations) [4]. RAG also provides data security as the entire data can be stored in a personal system without needing to give it to a third-party model. The basic functioning of a RAG system is shown in Figure 1.
As seen in Figure, RAG consists of three functions [4]:
- Indexing: The external data is stored in a vector database. This data can be obtained from multiples sources in different format. This data shall be converted to text and later into a high dimension numerical vector. This vector is stored in the vector database which can be retrieved based on the query.
- Retrieval: The system retrieves useful information from this database based on the user query. Similarity measuring techniques are used to find the most relevant information from the database.
- Generation: This retrieved information is given as additional context along with the query (prompt) and is fed to the LLM which generates response based on both the retrieved information and user query. In the next section, the architecture and working of the RAG system is explained in detail.
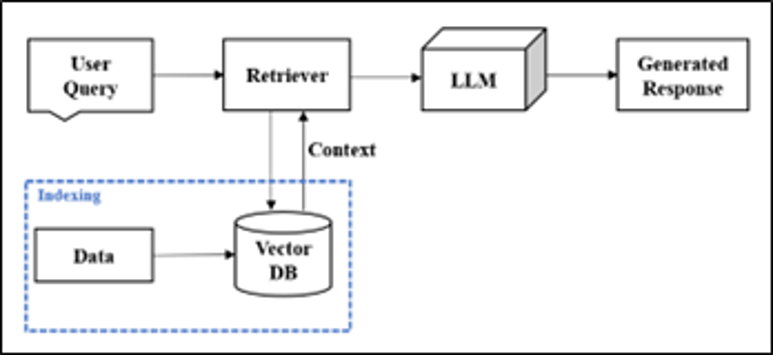
Figure 1: Overview of RAG System.
Working of RAG System
Figure 2 demonstrates the working architecture of the RAG system. Detailed explanation of the working is given below.
- Data Source
For a RAG system, a large data source which can be multiple files or single file of different formats like PDF, HTML, Word, Excel, etc., can be used. From these documents, raw text is extracted and divided into multiple smaller sections through a process called chunking.
- Chunking
Chunking involves splitting of the large text data into smaller text segments based on some criteria defined by the user. This process allows the large data to be utilized by the LLM to generate response accurately. Based on the user query, only the chunks containing relevant information needed to answer the query are retrieved and passed to the model. This ensures that the model’s maximum input word limit is not exceeded by giving the entire document and it also enables faster response from the model. There are multiple strategies used for chunking like: fixed length chunking - where the number of words and delimiter for splitting is predetermined, dynamic chunking - where an algorithm is used to decide the splitting strategy, or semantic chunking - where contextually similar sentences (sentences on same topic/similar idea) are grouped together into chunks. There are numerous other methods too and the method to choose is purely based on the use case at hand.
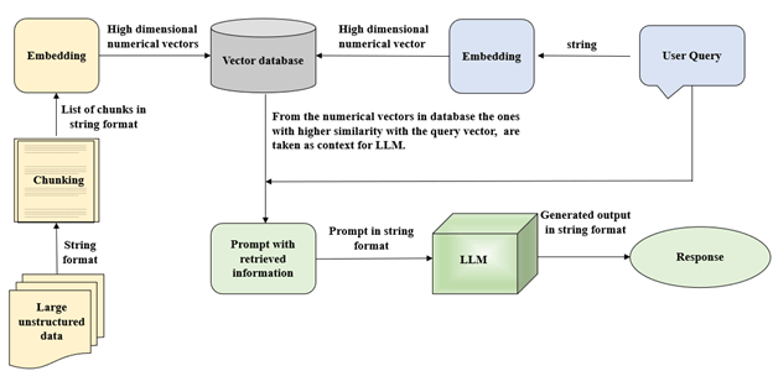
Figure 2: Detailed architecture of RAG.
- Data Embedding
Embedding is a technique which converts text into numerical vectors in a high-dimension space, which can then be used by models to understand the meaning of text [5]. This means that text groups with similar meanings will have embeddings that are closer together in the vector space. The chunks of data are embedded into vectors using an embedding technique suitable for the use case. The input user query also undergoes embedding with the same embedding model used for the data.
- Load Embeddings to Vector Database
The embedded document chunks must be indexed and stored in a vector database for easy retrieval. Unlike traditional databases, vector database stores data in numerical vectors which enables efficient storage, retrieval, and manipulation of the data. Hence, the retrieval of chunks which are contextually the most relevant to the user query can be achieved by using vector database.
- Data Retrieval
Data retrieval is the key step in RAG that involves accessing relevant information from the vector database to improve the responses generated by the model. The embedded input query is used to search through the vector database to retrieve the most relevant vector chunks of information. For this, the retrieval system computes the similarity scores between the query vector and the vector of chunks within the database. The chunks with the highest similarity score are retrieved and used as additional information for the LLM to generate accurate responses [6]. The number of chunks retrieved depends on either a predefined number assigned by the user or a threshold value where all chunks which score above this value are retrieved.
- Response Generation
The prompt for LLM is framed based on the particular use case. Using the retrieved information from the vector database and user query, a prompt is framed for generating the response from the LLM. Based on this prompt, the model generates the response as required by the user. In the next section, we will see a practical implementation of RAG integrated with Gemini [7], a powerful LLM by Google DeepMind for automotive system requirement generation.
System Requirement Generation Using RAG
Historical system requirement data in PDF format is used as an input for RAG. These PDFs are first converted into text and then divided into manageable chunks using a character-based splitter. Each chunk is then embedded using Google's Vertex AI text embeddings [8] into high dimension vectors. These embedded vectors are stored in a vector database named Chroma [9]. When a user submits a query to generate specific system requirements, the most similar text chunks based on this query are retrieved from the Chroma database by choosing the embedded chunks with the highest similarity score with the embedded query vector. This retrieved information is then passed into the Gemini model along with the prompt to generate accurate and focused system requirements. The parameters and model hyper-parameters used for the RAG system are given in Table 1.
Table 1: RAG System Parameters
|
Database
|
Automotive system document - 1
|
Automotive system document - 2
|
|
Size (in MB)
|
5.2
|
12.6
|
|
Number of pages in file
|
238
|
278
|
|
Framework
|
Langchain
|
|
Text splitter
|
Character text splitter
|
|
Separator: Character the delimiter for chunking.
|
“.”
|
|
Chunk size: Maximum characters allowed in a chunk.
|
1000
|
|
Chunk overlap: The number of characters from previous chunk that is overlapping with the next chunk for the chunks to be more cohesive.
|
400
|
|
Total number of chunks: Total number of chunks made from both the pdf files.
|
1686
|
|
Embedding model: Google generative AI embedding model used
|
embedding-001
|
|
Vector database: Open-source vector database
|
Chroma
|
|
LLM: Multimodal LLM by Google
|
Gemini-Pro
|
|
Temperature [10]: Determines the degree of randomness in the response generated. For low value, the LLM will always produce same output for the same input.
|
0
|
|
Top-P [10]: Chooses a token1 from tokens with a cumulative probability of given value. Low value is used for less random response.
|
0.1
|
|
Maximum output token: Maximum number of tokens that can be generated by the LLM.
|
2048
|
|
1 – Complex text is split into manageable units called tokens for the model to analyse them better [5]. Example: the statement ‘It’s over 9000’ can be split into three tokens – ‘It’s’, ‘over’, ‘9000’.
|
To showcase the efficiency of using RAG for system requirement generation, a comparison was made between the system requirements generated by the Gemini model using prompt engineering (with no additional information regarding the query) and by using RAG where this technique provided the model with additional information based on query.
An example of the requirements generated by both systems are given below. In this example, the user query was to generate the system requirements for an airbag system of a four-wheeler. The system without RAG generated the requirements using the prompt and the pre-trained knowledge of Gemini, while the system with RAG utilized the retrieved information from the database along with the prompt. From the generated responses, it is understood that RAG enabled the model to produce more detailed requirements which were based on the features mentioned in the historical system requirement data, whereas the responses without RAG were too generic as shown below. Instead of generating new functional requirements, the response mostly explained the function of airbags and how it will protect the passengers. The model with context retrieved from RAG generated detailed requirements for various types of airbags and how it can be placed to protect the passengers. It also showcased when each airbag should be deployed based on its function. To give an instance, the front airbags shall not be deployed for rollovers or side collisions, but the side curtain airbags shall be inflated. Other key requirements related to crash sensor, airbag control module and how the airbag should not be inflated when the seat is unoccupied to avoid unnecessary cost were generated by the model using retrieved context.
The model was able to generate these features only due to the additional information given along with prompt using RAG. Thus, RAG helped to access features from multiple documents at once and avoid the need to manually provide the context from which the requirements need to be generated.
System requirements generated by the model using prompt engineering:
Airbag System Requirements for a Four-Wheeler
- FR-1: The airbag system shall deploy airbags within a specified time frame (e.g., within 25 milliseconds of a triggering event).
- FR-2: The airbags shall deploy in a controlled manner to minimize the risk of injury to occupants.
- FR-3: The airbags shall provide protection for the head, neck, and chest of occupants in the event of a collision.
- FR-4: The airbags shall meet or exceed applicable safety standards (e.g., UN ECE R94).
- FR-5: The airbag system shall deflate the airbags rapidly after deployment to minimize the risk of secondary injuries.
- FR-6: The airbag system shall continuously monitor its components and provide diagnostic information to the electronic control unit (ECU).
System requirements generated by the model using RAG:
Airbag System Requirements for a four-wheeler
- FR-1: The vehicle shall be equipped with front airbags.
- FR-2: The front airbags shall not deploy in minor frontal collisions, side collisions, rear collisions, or rollovers.
- FR-3: The vehicle shall be equipped with seat-mounted side airbags in the front seats.
- FR-4: The seat-mounted side airbags shall inflate in the event of a severe side impact or a severe offset frontal impact.
- FR-5: The vehicle shall be equipped with curtain airbags.
- FR-6: The curtain airbags shall inflate only if a severe side impact occurs, or if the vehicle rolls over.
- FR-7: The vehicle shall be equipped with an airbag status indicator.
- FR-8: The airbag status indicator shall display the status of the passenger front airbag.
- FR-9: The passenger front airbag shall be OFF when the seat is unoccupied.
- FR-10: The vehicle shall be equipped with a driver knee airbag.
- FR-11: The driver knee airbag shall inflate in the event of a severe frontal collision.
- FR-12: The vehicle shall be equipped with a rear-seat center airbag.
- FR-13: The rear-seat center airbag shall inflate in the event of a severe side impact or a severe offset frontal impact.
- FR-14: The vehicle shall be equipped with an airbag control module.
- FR-15: The airbag control module shall monitor the status of the airbags and deploy them in the event of a collision.
- FR-16: The airbag control module shall be able to communicate with the vehicle's other electronic control modules.
- FR-17: The vehicle shall be equipped with a crash sensor.
- FR-18: The crash sensor shall detect the severity of a collision and send a signal to the airbag control module.
- FR-19: The crash sensor shall be located in a position where it can accurately detect the severity of a collision.
Conclusion
Automotive industry is witnessing a major shift with the adoption of autonomous driving, connectivity, software defined vehicles (SDVs), and electronic control unit (ECU) consolidation. This will result in more complex systems as compared to the ones seen now. The starting point of automotive software development cycle is system engineering which needs to be done with utmost care and efficiency. The complex systems will have complex system requirements associated with it. Creating these complex system requirements manually will incur huge effort, time, cost, and is prone to human errors. With the adoption of GenAI along with RAG, the manual effort required for system requirement generation can be significantly reduced. By combining the pre-trained knowledge of LLMs along with the domain specific and historical system requirement data given to the LLM through RAG, the system requirement generation process can be accelerated. This will not only help with generating requirements that are contextually relevant and up to date but also help engineers to avoid manual effort of doing repetitive tasks and avoid human induced errors in the requirements.
Tata Elxsi can support OEMs and Tier ones in using GenAI and RAG for automotive system requirement generation. By utilizing historical system requirements and domain knowledge data of the OEMs and Tier Ones, new and improved system requirements can be generated using LLMs. With the additional data as context for the LLM, Tata Elxsi can ensure the generation of relevant system requirements. Additionally, this framework can be integrated with cloud service partner infrastructure of OEMs and Tier ones for accelerated implementation in further programs with scalability.
Authors
Practice Head, Virtualization
Tata Elxsi
Senior Engineer
Tata Elxsi