Blog
Sensor Virtualization using Artificial Intelligence & Machine Learning

A workflow for sensor virtualization using machine learning
The sensor virtualization process involves different stages: Feature selection and model training with selected input features, Prediction using the trained model, Performance evaluation and model selection, and Embedded implementation as shown in Figure 1. Each of these stages is explained below.
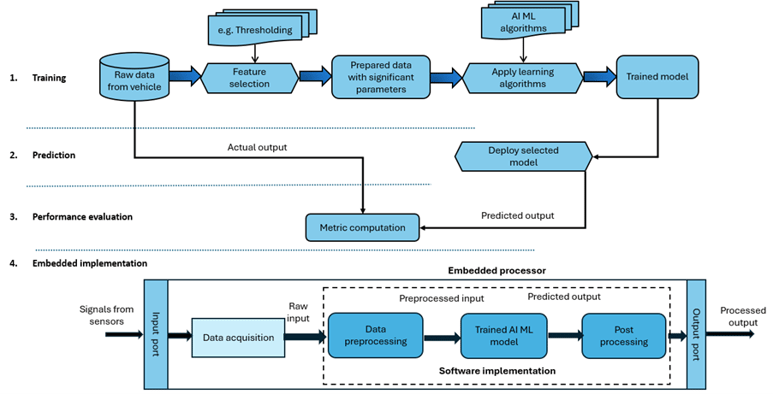
Figure 1: Sensor virtualization workflow
- Feature selection and model training - The dataset is first pre-processed to remove data samples with missing values and the data is normalized. To reduce computational complexity, various feature selection techniques are applied. The AI ML models are then trained with the significant parameters to predict the target sensor output. The dataset is split into two, training and test datasets. Each potential AI ML model is trained on the training dataset with and without feature selection. A part of the training dataset is used for validation of the model during training. The model parameters are adjusted to get the best validation results.
- Prediction using test dataset - Once the trained model is available, it is fed with the data samples from the test dataset. The predicted outputs for the unseen input data are collected. For each trained AI ML model, the prediction process is carried out for the same test dataset to compare the performance of different AI ML models.
- Performance evaluation and model selection - The performance of models is evaluated by comparing the predicted outputs with the actual target sensor outputs. A comprehensive set of error metrics are computed for performance evaluation. Apart from the metrics used to assess the accuracy of prediction, the training and inference times of each model is also computed to assess the model's efficiency and robustness. The model demonstrating high prediction accuracy, with minimal input features, and lower inference time can be chosen as the optimal one.
- Embedded implementation - The chosen trained model is then implemented on an embedded platform like an ECU. The embedded processor receives the raw inputs (selected sensors’ values and certain parameters over ECU interfaces) at regular intervals. They are pre-processed and fed to the trained model which predicts the target sensor value. The sampling rate of inputs are decided based on the inference time of the model in embedded platform.
Case study: Virtualization of motor temperature sensor
Dataset
The dataset used in this study is sourced from Kaggle [5] and consists of 185 hours of recordings from a permanent magnet synchronous motor (PMSM), sampled at a frequency of 2 Hz (one measurement every 0.5 seconds), resulting in approximately 1.33 million samples. The data is organized into 69 sessions, each identified by a unique ‘profile id’ indicating different operational scenarios. The dataset includes 12 variables, 11 input features and one target variable, the permanent magnet temperature (in °C), which is crucial for monitoring motor performance and preventing overheating. The input features capture various aspects of the motor’s operation, including motor speed, torque, currents and voltages in the d/q coordinates, coolant temperature, stator winding, and stator tooth temperatures. Each row in the dataset represents a specific operational state, capturing fluctuations in motor speed, thermal variations, and dynamic characteristics. The samples collected under diverse operational scenarios make the dataset valuable for developing predictive models.
Predictive modelling of motor temperature
Four different AI ML models were implemented in Python using scikit-learn machine learning library. They were trained on the dataset after applying various feature selection techniques. 75% of the dataset was used for training and the rest was used for performance evaluation. The parameters of the models as listed in Table 1 were tuned to get the best performance. The prediction accuracies of the models for different feature extraction methods are displayed in the bar chart shown in Figure 2. The prediction accuracy is given by 100-MAPE, where MAPE is mean absolute percentage error. It is noted that the random forest regressor outperforms other models with a prediction accuracy over 99%. The numbers marked above the bars give the number of features selected. With only three input features selected through thresholding technique, the random forest regression predicts the motor temperature with high accuracy. The three features are motor speed, stator yoke temperature, and d-component of voltage. The importance score of each input feature in predicting the motor temperature is derived through feature importance method and is shown in Figure 3. It is observed that the motor speed and stator yoke temperature highly influence the motor temperature.
| Model | Parameters |
| Random Forest Regressor | n_estimators=10 (number of trees) |
| Gradient Boosting Regressor | n_estimators=100 (number of boosting stages) |
| Multilayer Perceptron (MLP Regressor) | hidden_layer_sizes=(100, 50) (two hidden layers: 100 and 50 neurons) |
| max_iter =1000 (maximum iterations) |
Table 1: Model parameters
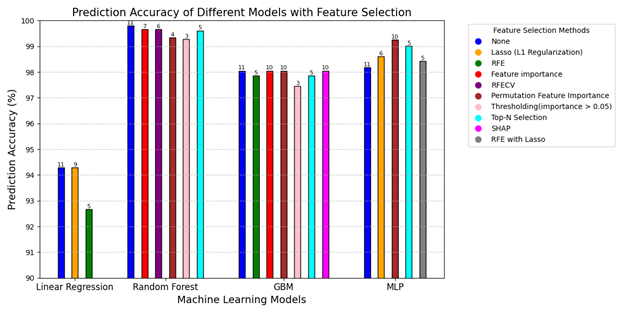
Figure 2: Prediction accuracies of AI ML models using various feature selection methods Table
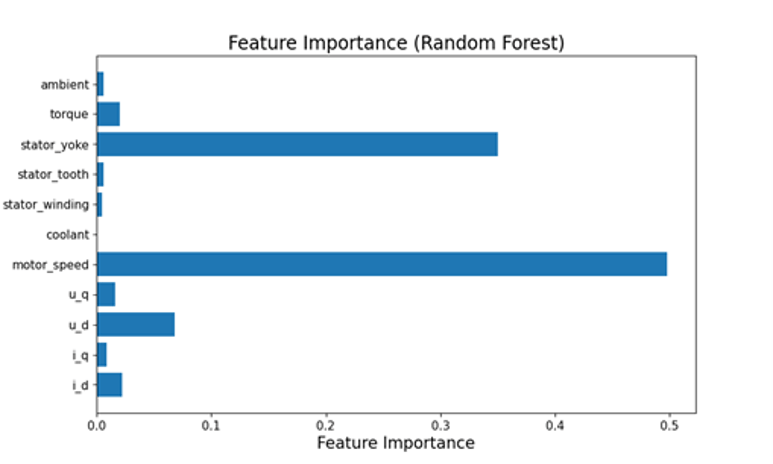
Figure 3: Importance scores of different input features for random forest model
The scatter plot showing actual and predicted temperature values using test data set for the random forest model is shown in Figure 4. It is observed that most of the points lie near the ideal line which demonstrates the efficacy of the model. Table 2 displays the error metrics computed for the random forest regression model with and without feature selection methods applied. The error metrics, remain consistently low across methods with different number of features selected, demonstrating high predictive accuracy. Although there is a slight drop in performance when fewer features are selected, the reduced number of features however results in faster computations. The three-quality metrics achieve nearly their maximum value of 1, indicating a perfect model fit.
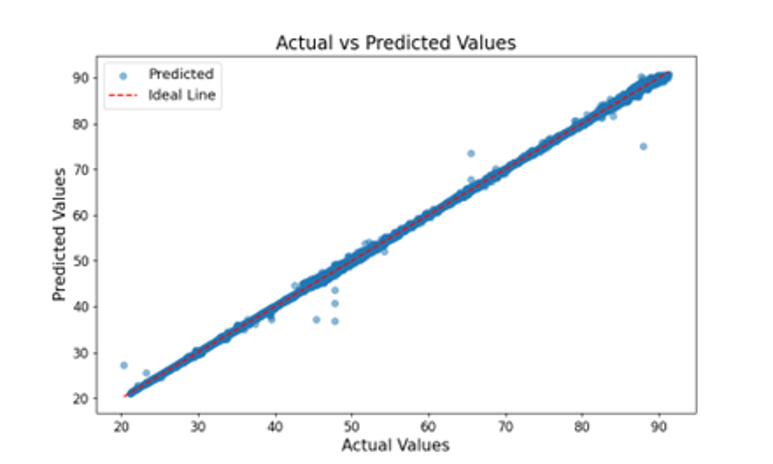
Figure 4: Scatter plot of actual versus predicted temperature values in testing phase for random forest model
|
Metrics |
None (11) |
Feature |
Recursive Feature Elimination with Cross Validation |
Top N |
Permutation |
Thresholding |
|
Mean Squared Error (MSE) |
0.06 |
0.1 |
0.1 |
0.11 |
0.26 |
0.33 |
|
Mean Squared Logarithmic Error (MSLE) |
0 |
0 |
0 |
0 |
0 |
0 |
|
Mean Absolute Error (MAE) |
0.1 |
0.16 |
0.16 |
0.18 |
0.28 |
0.32 |
|
Mean Absolute Percentage Error (MAPE) |
0.19% |
0.32% |
0.33% |
0.38% |
0.65% |
0.72% |
|
Median Absolute Error (MedAE) |
0.04 |
0.07 |
0.07 |
0.09 |
0.12 |
0.13 |
|
Symmetric Mean Absolute Percentage Error (SMAPE) |
0.19% |
0.32% |
0.33% |
0.38% |
0.65% |
0.72% |
|
R-squared (R²) |
1 |
0.99 |
0.99 |
0.99 |
0.99 |
0.99 |
|
Adjusted R-Squared |
1 |
0.99 |
0.99 |
0.99 |
0.99 |
0.99 |
|
Explained Variance Score |
1 |
0.99 |
0.99 |
0.99 |
0.99 |
0.99 |
|
Max Error |
12.87 |
13.79 |
12.72 |
12.25 |
12.37 |
11.13 |
|
Prediction accuracy (100-MAPE) |
99.81% |
99.67% |
99.66% |
99.61% |
99.34% |
99.27% |
Table 2: Performance metrics computed for random forest regression model with different feature selection techniques. The numbers within parenthesis indicate the number of features selected.
Realization on Raspberry Pi
The random forest prediction model, utilizing three significant input features (motor speed, stator yoke and u_d) was deployed on a Raspberry Pi 4 model B [6] embedded development board. The board was connected to a PC via Ethernet for two-way data communication using the SOME/IP protocol [7]. The experimental setup is shown in Figure 5. In this setup, the data values of the three input features were transmitted from the PC to the board and the predicted temperature value was received. A screenshot of data communication with embedded virtual sensor, as displayed on the PC monitor, is shown in the figure. The arrows point to the transmission and reception times. The total time for data transfer and prediction is approximately 50 ms, with the regression model taking only 5 ms to predict the temperature based on the input data.
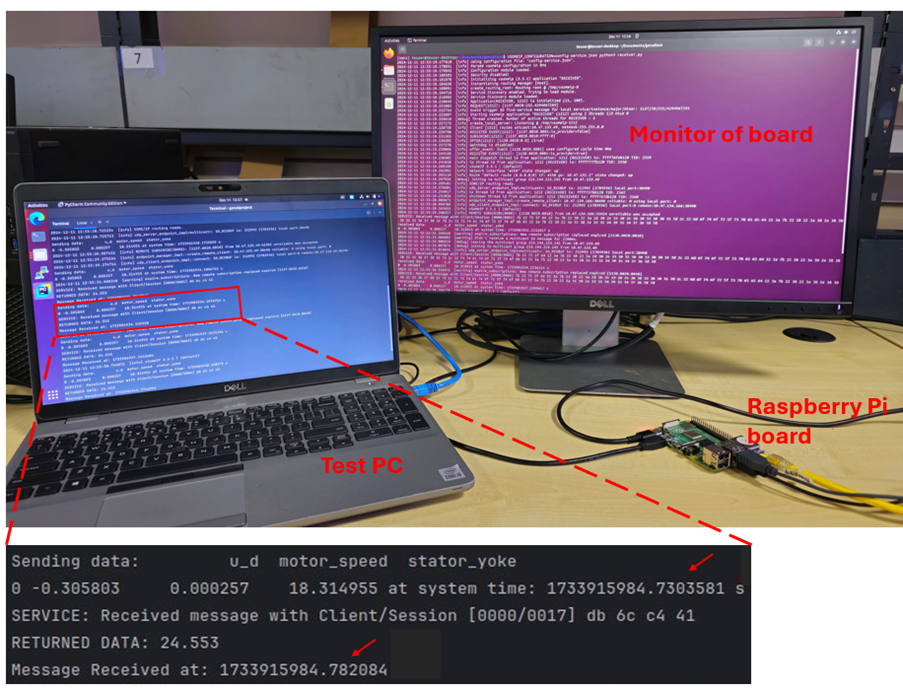
Figure 5: Virtual sensor experimental setup and screenshot of data communication
Authors